

Como te he comentado en los últimos episodios, ando metido en la implementación de una aplicación que me permita filtrar las peticiones que se realicen a mi servidor. Y es que si tienes tu servidor expuesto a internet, habrás visto que a todas horas llegan cientos de peticiones de todas partes del mundo. Sin embargo, muchas de esas peticiones, no están buscando conocer lo que tienes publicado. Es mas yo te diría que una gran parte de esas peticiones. Lo único que pretenden esas peticiones es buscar alguna vulnerabilidad, algún hueco, para colarse o para hacer algo nada ético, por lo menos a priori. Porque ¿que sentido que tienen en que busquen por .env, o por info.php, o similar?… La cuestión es que finalmente he puesto Shuul, que es como he llamado a la aplicación, en mi servidor, para ver como se comporta, y me he llevado una sorpresa con el consumo de CPU. Pero no el consumo de CPU de la propia aplicación sino con el de las base de datos que utilizo para guardar todas las peticiones. Así, en este episodio te cuento como he detectado el problema y como lo he solucionado.

El misterio del consumo de CPU de PostgreSQL
Sobre Shuul
Todo empezó hace alrededor de un mes cuando por un hackeo de Feedprees, decidimos utilizar una herramienta que había implementado para combinar los feeds de los distintos podcast de los integrantes de la red de Sospechosos Habituales.
Esta herramienta que inicialmente lo único que hacía era publicar en Telegram y Twitter, ahora comenzaba también a publicar el feed combinado de toda la red de Sospechosos Habituales.
Sin embargo, en el servidor donde tengo alojado la aplicación, hasta la fecha, tenía restringida las peticiones que se realizan al mismo. Me refiero a que solo se aceptaban peticiones provenientes de España. Al alojar el feed, esto era necesario cambiarlo para que estuviera accesible para todo el mundo. Y eso hice, simplemente, quitar las restricciones de acceso por país. Una configuración que tenía implementada en un plugin de Traefik, el proxy inverso que utilizo en mi servidor.
En ese momento, volví a ver la cantidad de peticiones extrañas y extravagantes que llegaban al servidor, y me decidí a implementar Shuul, que es una aplicación que estoy desarrollando en Rust y TypeScript, que se encarga de filtrar las peticiones que llegan al servidor, para bloquear las que son sospechosas y permitir las que son normales, o las que yo considere.
Para que te hagas una idea, en los últimos 3 días, mas o menos, han llegado unas 60.000 peticiones al servidor, de las cuales se han filtrado unas 20.000. Y tienes que contar que las reglas las he ido poniendo sobre la marcha, así que puedes hacerte una idea del volumen.
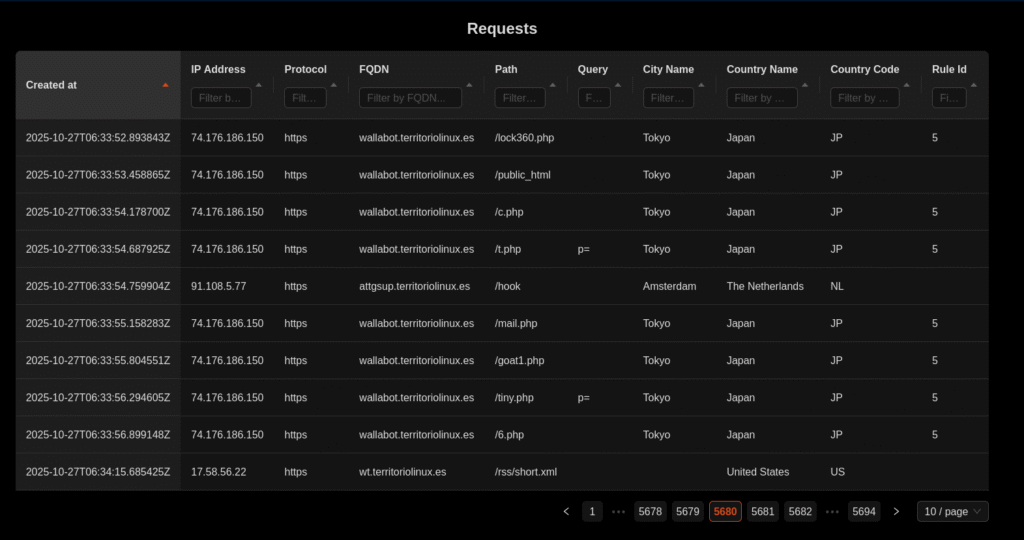
Durante esta última semana, finalmente, puse en marcha Shuul, que utiliza PostgreSQL como base de datos para guardar toda la información. Tanto las reglas que se utilizan, como las peticiones que llegan al servidor. Y fue en ese momento, cuando gracias a Beszel me di cuenta que la base de datos estaba consumiendo excesivo CPU. Y ahí comienza la investigación.
La investigación
Inicialmente pensé que el problema podía estar en la propia aplicación, en Shuul. Así que decidí implementar una serie de mejoras para reducir las peticiones a la base de datos. Implementé un sistema de cacheado tanto de las reglas como de las peticiones. Con ello, conseguí reducir el número de consultas a la base de datos, pero el consumo de CPU seguía siendo excesivo.
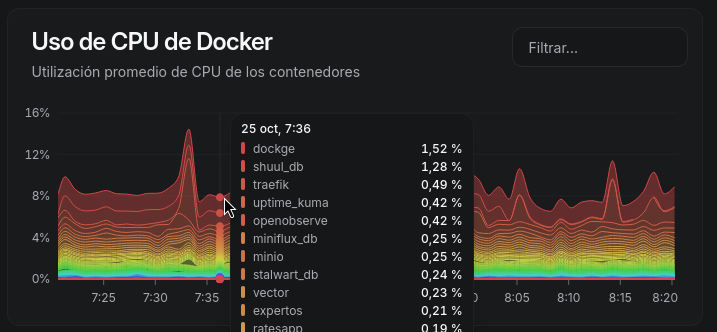
De esta manera, siempre, las reglas se encuentran en memora, y no es necesario ir a la base de datos para cada petición. Cuando se añade, modifica o elimina una regla, se actualiza la memoria cacheada, y primer problema solucionado. Por otro lado estaban las peticiones. En ese caso, las peticiones se guardaban cada vez que llegaba una nueva en la base de datos. Decidí, utilizar también un buffer con un tamaño configurable, inicialmente de 10, de forma que hasta que no se llenaba el buffer no se escribía en la base de datos. Sin embargo, con esto tampoco conseguí reducir el consumo de CPU.
El contenedor de PostgreSQL
El compose.yml donde esta Shuul y PostgreSQL es el siguiente,
services:
shuul:
image: atareao/shuul
container_name: shuul
init: true
restart: unless-stopped
environment:
RUST_LOG: debug
RUST_BACTRACE: full
RUST_ENV: production
DATABASE_URL: postgres://xxxxxx:xxxxxx@shuul_db:5432/shuul
PORT: 3000
SECRET: esto-es-un-secreto-que-no-se-puede-saber
MAXMIND_DB_PATH: /geo/GeoLite2-City.mmdb
CACHE_ENABLED: true
CACHE_SIZE: 20
depends_on:
shuul_db:
condition: service_healthy
restart: true
volumes:
- geo:/geo
networks:
- shuul
- proxy
labels:
traefik.enable: true
traefik.http.routers.shuul.rule: Host(`shuul.territoriolinux.es`)
traefik.http.routers.shuul.entrypoints: https
traefik.http.services.shuul.loadbalancer.server.port: 3000
shuul_db:
image: postgres:18-alpine
container_name: shuul_db
restart: unless-stopped
init: true
environment:
POSTGRES_USER: xxxxxxxx
POSTGRES_PASSWORD: xxxxxxxxxxxx
POSTGRES_DB: shuul
PGUSER: shuul
command: |
postgres -c logging_collector=on
-c log_directory=/tmp
-c log_filename=postgresql.log
-c log_statement=all
-c log_connections=on
-c log_disconnections=on
-c log_destination=stderr
-c log_rotation_age=1d
-c shared_preload_libraries=pg_stat_statements
-c pg_stat_statements.track=all
volumes:
- pgdata:/var/lib/postgresql/data
healthcheck:
test:
- CMD-SHELL
- sh -c 'pg_isready -U shuul -d shuul'
start_period: 30s
start_interval: 10s
interval: 30s
timeout: 5s
retries: 3
networks:
- shuul
volumes:
geo:
external: true
pgdata: {}
networks:
shuul:
external: true
proxy:
external: true
x-dockge:
urls:
- https://shuul.territoriolinux.esIndicar que el comando que aparece, lo añadí a posteriori, tal y como te comentaré mas adelante, pero es como lo tengo actualmente.
Inicialmente, el contenedor de PostgreSQL lo tenía con la imagen postgres:18-alpine, que está basado en Alpine, y que es la distribución que utilizo para mis propios contenedores. Pensé que podía ser un problema de ese contenedor, basando mi suposición en absolutamente nada. Así que decidí cambiar la imagen a postgres:18-latest, que es el que está basado en Debian, sin embargo, el consumo de CPU en lugar de disminuir aumentó. Así que descarté esa posibilidad, obviamente.
Rainfrog
El siguiente paso fue investigar si había conexiones bloqueantes en la base de datos. Para conectarme a la base de datos, sin necesidad de levantar permanentemente otro servicio, decidí utilizar rainfrog que es una herramienta que te permite realizar consultas a PostgreSQL desde la línea de comandos. Realmente es una TUI (Text User Interface) que te permite conectarte a la base de datos y realizar consultas. Lo cual lo hace muy sencillo. Y para mas comodidad, lo hice con un script en bash como el que te muestro a continuación,
docker run \
-it \
--rm \
--name rainfrog \
--network shuul \
-e db_driver="postgresql" \
-e username="xxxxxxxx" \
-e password="xxxxxxxx" \
-e hostname="shuul_db" \
-e db_port="5432" \
-e db_name="shuul" \
achristmascarl/rainfrog:latestComo ves tanto el docker de Rainfrog como el de Shuul están en la misma red de Docker, la red shuuul, por lo que se pueden comunicar sin problemas, de forma que no lo necesito exponer ni a internet ni a otros servicios.
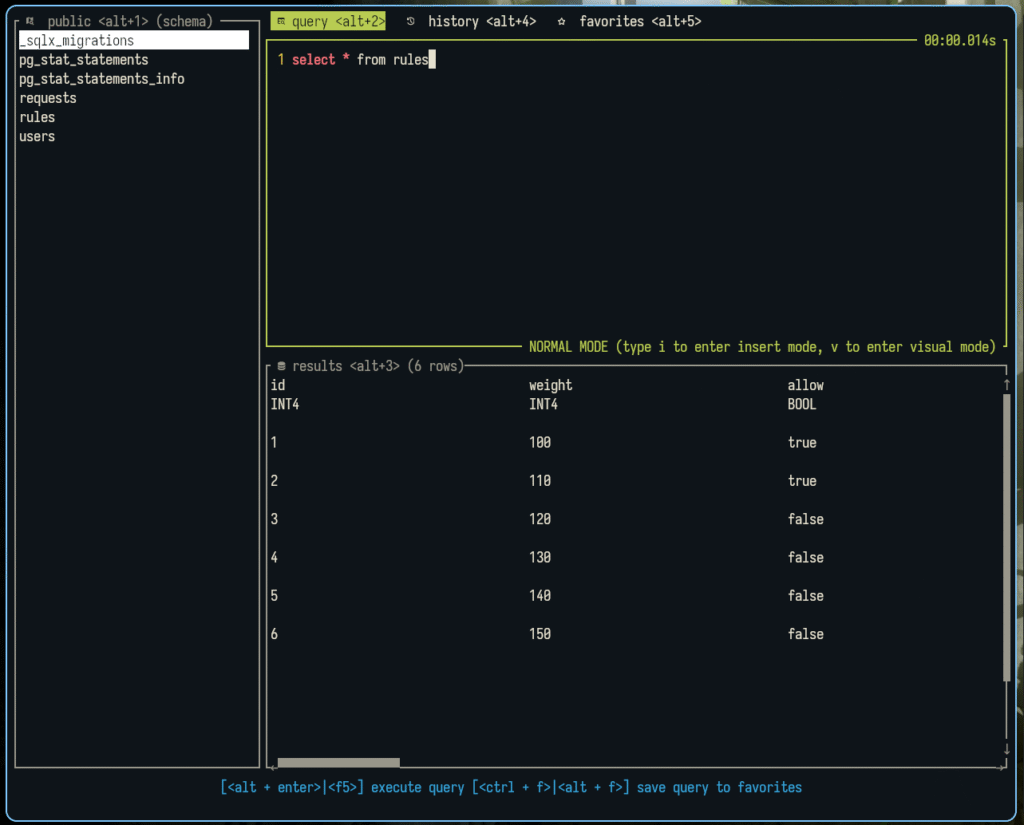
Aquí es cuando activé los complementos de PostgreSQL, y en particular el de pg_stat_statements, que me permite obtener estadísticas de las consultas que se realizan a la base de datos. Con ello, pude ver que había muchas conexiones activas, y que muchas de ellas estaban en estado active, lo cual indicaba que estaban realizando alguna operación. Para ello, añadí el comando que aparece en el compose.yml,
postgres -c logging_collector=on
-c log_directory=/tmp
-c log_filename=postgresql.log
-c log_statement=all
-c log_connections=on
-c log_disconnections=on
-c log_destination=stderr
-c log_rotation_age=1d
-c shared_preload_libraries=pg_stat_statements
-c pg_stat_statements.track=allY a continuación ejecuté la siguiente consulta con Rainfrog,
- CREATE EXTENSION pg_stat_statements;Dejé un tiempo la base de datos funcionando, y luego ejecuté las siguientes consultas para ver el estado de las conexiones, para ver si había conexiones bloqueantes, y para ver las consultas que se estaban realizando.
SELECT
count(*) AS total_conexiones_activas
FROM
pg_stat_activity
WHERE
state <> 'idle';SELECT
state,
count(*) AS cuenta_por_estado
FROM
pg_stat_activity
GROUP BY
state
ORDER BY
cuenta_por_estado DESC;- verificar bloqueos
SELECT
blocking_activity.pid AS blocking_pid,
blocking_activity.usename AS blocking_user,
blocking_activity.query AS blocking_query,
blocked_activity.pid AS blocked_pid,
blocked_activity.usename AS blocked_user,
blocked_activity.query AS blocked_query,
blocked_activity.wait_event_type,
blocked_activity.wait_event
FROM
pg_catalog.pg_locks blocked_locks
JOIN
pg_stat_activity blocked_activity ON blocked_activity.pid = blocked_locks.pid
JOIN
pg_catalog.pg_locks blocking_locks ON blocking_locks.locktype = blocked_locks.locktype
AND blocking_locks.database IS NOT DISTINCT FROM blocked_locks.database
AND blocking_locks.relation IS NOT DISTINCT FROM blocked_locks.relation
AND blocking_locks.page IS NOT DISTINCT FROM blocked_locks.page
AND blocking_locks.tuple IS NOT DISTINCT FROM blocked_locks.tuple
AND blocking_locks.transactionid IS NOT DISTINCT FROM blocked_locks.transactionid
AND blocking_locks.classid IS NOT DISTINCT FROM blocked_locks.classid
AND blocking_locks.objid IS NOT DISTINCT FROM blocked_locks.objid
AND blocking_locks.objsubid IS NOT DISTINCT FROM blocked_locks.objsubid
AND blocking_locks.pid != blocked_locks.pid
JOIN
pg_stat_activity blocking_activity ON blocking_activity.pid = blocking_locks.pid
WHERE
NOT blocked_locks.granted
ORDER BY
blocking_activity.pid;Sin embargo nada de esto me decía que hubiera un problema evidente. Así que decidí revisar los logs de PostgreSQL para ver que estaba ocurriendo.
Los logs de PostgreSQL
En el comando que añadí al contenedor de PostgreSQL, activé el logging de conexiones y desconexiones, así como el logging de todas las sentencias SQL que se ejecutaban. De esta manera, pude ver en los logs que había una gran cantidad de conexiones y desconexiones que se realizaban cada segundo. Y fue cuando empecé a sospechar de esas conexiones y desconexiones continuas. Por que si te das cuenta se realizan cada poquísimo tiempo. ¿Quien lo hacía?
2025-10-25 05:59:50.757 UTC [1282] LOG: connection authorized: user=shuul database=shuul application_name=pg_isready
2025-10-25 06:01:17.113 UTC [1857] LOG: connection authorized: user=shuul database=shuul application_name=pg_isready
2025-10-25 06:01:17.115 UTC [1857] LOG: disconnection: session time: 0:00:00.003 user=shuul database=shuul host=[local]
2025-10-25 06:01:18.191 UTC [1864] LOG: connection received: host=[local]
2025-10-25 06:01:18.192 UTC [1864] LOG: connection authenticated: user="shuul" method=trust (/var/lib/postgresql/18/docker/pg_hba.conf:117)
2025-10-25 06:01:18.192 UTC [1864] LOG: connection authorized: user=shuul database=shuul application_name=pg_isready
2025-10-25 06:01:18.193 UTC [1864] LOG: disconnection: session time: 0:00:00.002 user=shuul database=shuul host=[local]
2025-10-25 06:01:19.267 UTC [1871] LOG: connection received: host=[local]
2025-10-25 06:01:19.268 UTC [1871] LOG: connection authenticated: user="shuul" method=trust (/var/lib/postgresql/18/docker/pg_hba.conf:117)
2025-10-25 06:01:19.268 UTC [1871] LOG: connection authorized: user=shuul database=shuul application_name=pg_isready
2025-10-25 06:01:19.270 UTC [1871] LOG: disconnection: session time: 0:00:00.003 user=shuul database=shuul host=[local]
2025-10-25 06:01:20.349 UTC [1878] LOG: connection received: host=[local]
2025-10-25 06:01:20.350 UTC [1878] LOG: connection authenticated: user="shuul" method=trust (/var/lib/postgresql/18/docker/pg_hba.conf:117)
2025-10-25 06:01:20.350 UTC [1878] LOG: connection authorized: user=shuul database=shuul application_name=pg_isready
2025-10-25 06:01:20.352 UTC [1878] LOG: disconnection: session time: 0:00:00.003 user=shuul database=shuul host=[local]
2025-10-25 06:01:21.427 UTC [1886] LOG: connection received: host=[local]
2025-10-25 06:01:21.429 UTC [1886] LOG: connection authenticated: user="shuul" method=trust (/var/lib/postgresql/18/docker/pg_hba.conf:117)
2025-10-25 06:01:21.429 UTC [1886] LOG: connection authorized: user=shuul database=shuul application_name=pg_isready
2025-10-25 06:01:21.431 UTC [1886] LOG: disconnection: session time: 0:00:00.004 user=shuul database=shuul host=[local]
2025-10-25 06:01:22.514 UTC [1894] LOG: connection received: host=[local]
2025-10-25 06:01:22.516 UTC [1894] LOG: connection authenticated: user="shuul" method=trust (/var/lib/postgresql/18/docker/pg_hba.conf:117)
2025-10-25 06:01:22.516 UTC [1894] LOG: connection authorized: user=shuul database=shuul application_name=pg_isready
2025-10-25 06:01:22.518 UTC [1894] LOG: disconnection: session time: 0:00:00.004 user=shuul database=shuul host=[local]El responsable de esas conexiones y desconexiones continuas era el propio healthcheck que tenía implementado en el contenedor de PostgreSQL. Y es que cada segundo, se realizaba una conexión a la base de datos para comprobar si estaba disponible o no. Y claro, cada conexión y desconexión consume recursos, y si se realizan continuamente, el consumo de CPU se dispara. Y que ahora queda de la siguiente, manera,
healthcheck:
test:
- CMD-SHELL
- sh -c 'pg_isready -U shuul -d shuul'
start_period: 30s
start_interval: 10s
interval: 30s
timeout: 5s
retries: 3Fue pasar de 1s a 30s y el consumo de CPU de PostgreSQL se redujo drásticamente. Y es que ahora, en lugar de realizar 60 conexiones y desconexiones por minuto, solo se realizan 2.
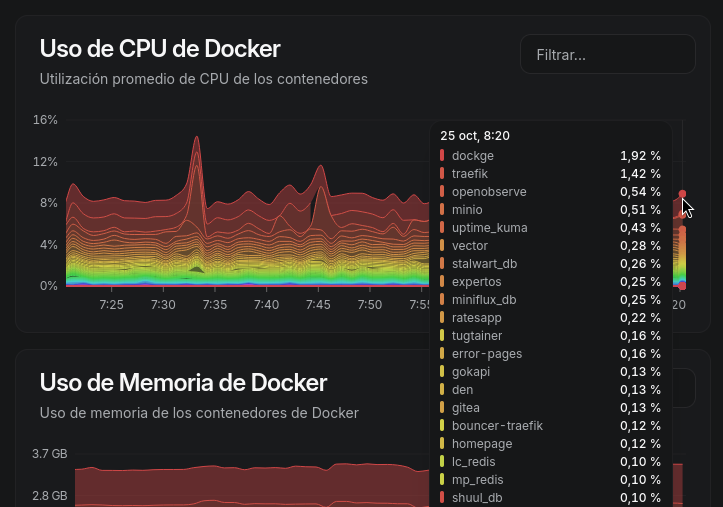
Último cambio, pero eh Shuul
Tanto investigar me llevó a pensar que eso de compilar cada uno de los patrones en cada una de las peticiones, podía ser un problema. Así que decidí hacer un último cambio en Shuul, y es que ahora, las reglas se compilan una sola vez, cuando se cargan desde la base de datos, y no en cada petición. Aunque tengo que decirte que actualmente no he observado un cambio significativo en el consumo de CPU, pero es un cambio que tenía que hacer.
Conclusión
La verdad es que ha sido todo un misterio el consumo de CPU de PostgreSQL, y la solución ha sido bastante sencilla. Simplemente, ajustar el healthcheck del contenedor de PostgreSQL para que no realice conexiones tan frecuentes. Y es que a veces, los problemas mas complejos tienen soluciones muy simples.
Pero gracias a todo esto, he podido probar a fondo Shuul, y realizar cambios en la aplicación para mejorar su rendimiento y funcionalidad. Así que al final, todo ha sido positivo.
Más información,