








El otro día leí un artículo referente al reconocimiento óptico de caracteres (OCR) en Ubuntu, y me quedó ahí, grabado en la mente, a la espera de que llegara el fin de semana para probarlo. Así que esta mañana, me he dedicado a investigar un poco en referencia a este tema, y he probado dos alternativas.
La primera de las dos alternativas es la de instalar un paquete creado por Geza Kovacs. Que se puede instalar desde Launchpad, añadiendo al repositorio de las maneras conocidas:
sudo -v
sudo add-apt-repository ppa:gezakovacs/pdfocr
sudo apt-get update
sudo apt-get install pdfocr
para hacerlo funcionar simplemente:
pdfocr -i inputfile.pdf -o outputfile.pdf
Ya está. El archivo tiene una capa de texto incrustada, que puedes utilizar para copiar y pegar.
La segunda alternativa es más gráfica y me gusta más. Consiste en instalar desde el repositorio de Ubuntu gscanpdf
sudo apt-get install tesseract-ocr-spa gscan2pdf
Para hacerlo funcionar, corremos gscan2pdf desde un terminal, y obtendremos la siguiente imagen:
importamos las imágenes que queramos someter al OCR
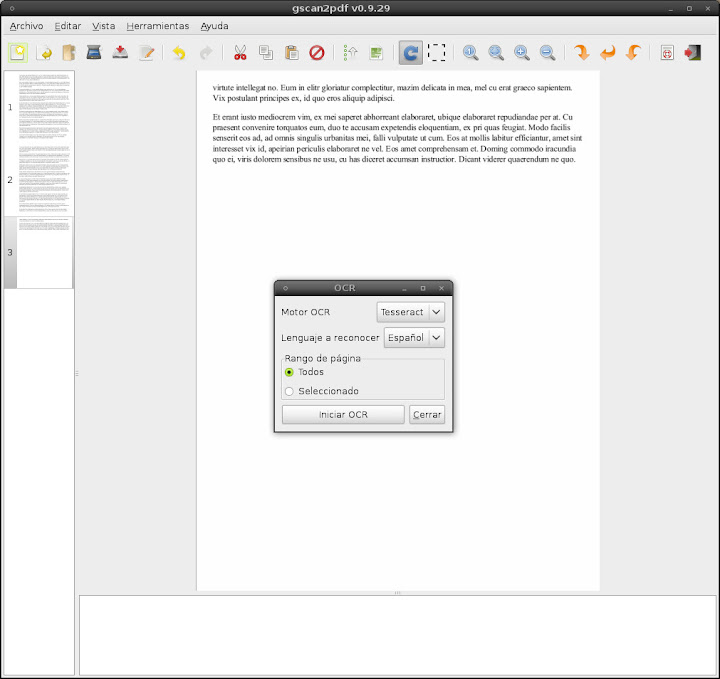
En herramientas seleccionamos OCR, y en la ventana que nos sale seleccionamos el motor de OCR que queramos utilizar:
En la parte inferior, veremos los caracteres detectados por el OCR. En la prueba que he realizado tengo que decir que el resultado fue bastante deficiente. No se si es por utilizar Lorem Ipsum, pero no me resultó nada alentador.
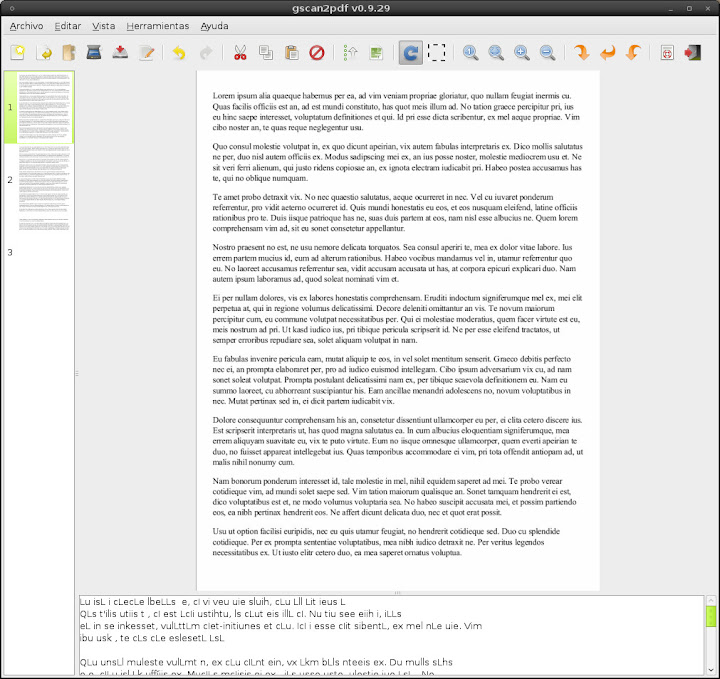
He probado con varios motores:
– GOCR: Resultados decepcionantes (casi tardas más en corregir que en escribirlo tu mismo).
– TESSERACT: Muy buen OCR. Apenas tuve que modificar nada.
Muchas gracias por compartir la información.
yo lo pensaría bien para escanear documentos como Lorem Ipsum ya que Tesseract intenta predecir palabras mediante el idioma y mejorar el resultado OCR.